近日,全球人工智能顶会AAAI 2021以虚拟形式在线召开,并于会前公布了论文收录结果。AAAI 2021投稿论文总数达到“惊人的高技术水平”,9034篇投稿论文中,7911篇接受评审,最终1692篇被录取,录取率为21%;百度再创佳绩,一举贡献24篇优质学术论文,涵盖计算机视觉、自然语言处理、知识图谱、量子机器学习等多个领域,展示出行业领先的AI技术实力,同时这些技术创新和突破将有助于推进智能对话、智能办公、智慧医疗、智慧金融、智能交通等场景的落地应用,加速中国智能经济时代的到来。
资料显示,AAAI是国际AI领域历史最悠久、涵盖内容最广泛的国际顶级学术会议之一。会议的目的是促进人工智能(AI)领域的研究,以及人工智能研究人员、从业人员、科学家和附属学科工程师之间的科学交流。
以下为百度AAAI2021部分收录论文的亮点集锦。
1、ERNIE-ViL:融合场景图知识的视觉-语言跨模态预训练技术
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graph
论文链接:https://arxiv.org/abs/2006.16934
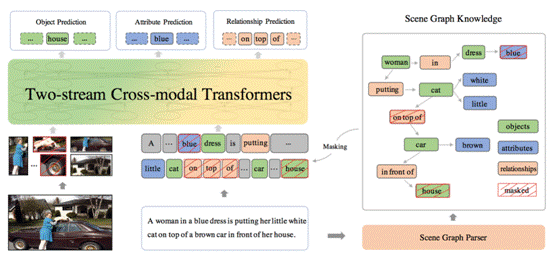
视觉-语言预训练的目标是通过对齐语料学习多模态的通用联合表示,将各个模态之间的语义对齐信号融合到联合表示中,从而提升下游任务效果。已有的视觉语言预训练方法在预训练过程中没有区分普通词和语义词,学到的联合表示无法刻画模态间细粒度语义的对齐,如场景中物体(objects)、物体属性(attributes)、物体间关系(relationships)这些深度理解场景所必备的细粒度语义。本文提出了知识增强的视觉-语言预训练技术ERNIE-ViL,将包含细粒度语义信息的场景图先验知识融入预训练过程,创建了物体预测、属性预测、关系预测三个预训练任务,在预训练过程中更加关注细粒度语义的跨模态对齐,从而学习到能够刻画更好跨模态语义对齐信息的联合表示。作为业界首个融入场景图知识的视觉语言预训练模型,ERNIE-ViL在视觉问答、视觉常识推理、引用表达式理解、跨模态文本检索、跨模态图像检索等5个多模态典型任务上取得了SOTA效果,同时,在视觉常识推理VCR榜单上取得第一。
 2、基于实体结构建模的文档级关系抽取
2、基于实体结构建模的文档级关系抽取
Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
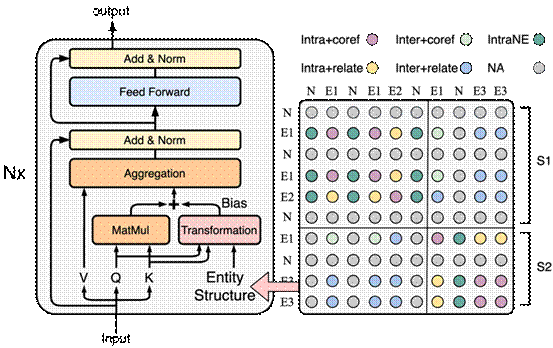
文档级关系抽取是近两年来信息抽取的热门研究方向之一,针对其涉及多个实体提及(Entity Mention)之间的复杂交互这一挑战,本文创新性地提出了实体结构(Entity Structure)这一概念,以依赖(dependency)的形式,对实体提及在文档中的分布进行定义,并设计了结构化自注意力网络(SSAN)在上下文编码的同时对实体结构进行建模。实验表明,SSAN能够有效地在深度网络中引入实体结构的先验,指导注意力机制的传播,以增强模型对实体间交互关系的推理能力。SSAN在包括DocRED在内的多个常用文档级关系抽取任务上取得了当前最优效果。
 3、MVFNet: 用于高效视频识别的多视角融合网络
3、MVFNet: 用于高效视频识别的多视角融合网络
MVFNet: Multi-View Fusion Network for Efficient Video Recognition
论文链接:https://arxiv.org/abs/2012.06977
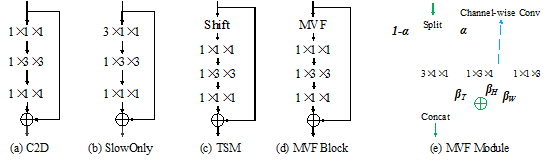
视频识别作为视频理解的基础技术,是近几年非常热门的计算机视觉研究方向。现有的基于3D卷积网络的方法识别精度优异但计算量偏大,基于2D网络的方法虽然相对轻量但精度不及3D卷积网络。本文提出一种轻量的多视角融合模块(MVF Module)用于高效率且高性能的视频识别,该模块是一个即插即用的模块,能够直接插入到现有的2D卷积网络中构成一个简单有效的模型,称为MVFNet。此外,MVFNet可以视为一种通用的视频建模框架,通过设置模块内的参数,MVFNet可转化为经典的C2D, SlowOnly和TSM网络。实验结果显示,在五个视频benchmark(Kinetics-400, Something-Something V1 V2, UCF101, HMDB51)上,MVFNet仅仅使用2D卷积网络的计算量就能够取得与当前最先进的3D卷积网络媲美甚至更高的性能。
 4、一种基于关键点聚合网络的实时任意形态文字端到端框架
4、一种基于关键点聚合网络的实时任意形态文字端到端框架
PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network
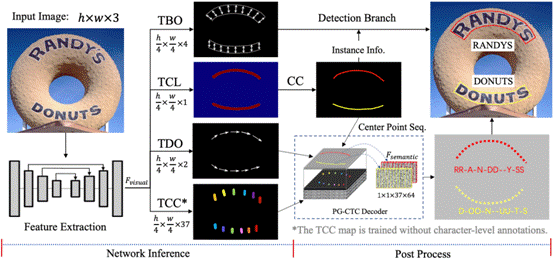
任意形态文字阅读问题近几年受到越来越多的关注,是学术界的研究热点。然而,现有的解决方案大多数是建立在检测模块和识别模块两阶段级联的框架或者基于单字的方法,这些方法往往受困于比较耗时的NMS、区域特征提取(ROI)等操作,甚至是昂贵的单字粒度标注方式。针对上述问题,本文提出了一种全新的实时的单阶段任意形态文字端到端框架, 命名为PGNet。PGNet在模型单阶段前向推理的过程中能够将端到端文字提取需要用到的中心线、上下边界位置偏差、阅读方向、和每个像素点字符类别预测信息全部获取到位。紧接着,根据本文提出的核心思想-关键点聚合(Point Gathering),将标准CTC Decoder改造成了PG-CTC Decoder, 让其能够根据2D空间上的文本实例所在的中心线像素点位置进行对应字符类别概率向量聚合,然后直接解码出文本实例的识别结果。PGNet无需额外的字符粒度标注成本,轻量化模型配置版本在精度可比以往SOTA方法同时加速超过1倍,在任意形态文本集合Total-Text上最优速度达到46.7FPS(NVIDIA-v100显卡),端到端精度可以达到58.4%,该方法为实时或者端上设备的OCR应用带来广泛的遐想。
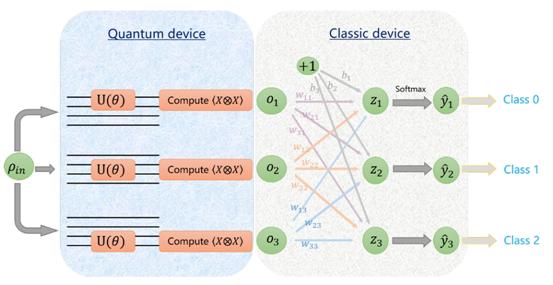
 5、基于变分影子量子学习的分类算法
5、基于变分影子量子学习的分类算法
VSQL: Variational Shadow Quantum Learning for Classification
论文链接:https://arxiv.org/abs/2012.08288
机器学习擅长处理结构化的数据特征,其中分类问题因为其泛用性一直处于核心的研究地位。近年来随着量子机器学习的兴起,研究者们开始探索如何采用量子神经网络去完成针对经典和量子数据的分类任务。然而由于目前量子设备的局限性,训练过程中会出现诸多问题,例如:参数过多,训练代价太大,测试精度不高等等。针对这些不足,本文提出了一种基于“变分影子量子学习”的分类算法,该算法采用了一种特殊的“影子电路”组成的量子神经网络架构,通过滑动的影子电路提取特征信息。该工作基于百度飞桨上的量子机器学习工具集量桨(qml.baidu.com)研发,数值实验结果表明该算法在相比于已有的量子分类算法具有更强大分类能力的同时,还大幅减少了网络参数,降低了训练代价。
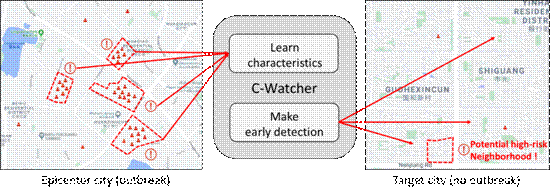
 6、C-Watcher:一个新冠肺炎高风险小区预警框架
6、C-Watcher:一个新冠肺炎高风险小区预警框架
C-Watcher: A Framework for Early Detection of High-Risk Neighborhoods Ahead of COVID-19 Outbreak
论文链接:https://arxiv.org/abs/2012.12169
新型冠状病毒病(COVID-19)已经对日常的工作产生了严重的影响,并且仍在全世界肆虐。现有的非药物干预的解决方案通常需要及时、准确地选择一个区域进行出行限制甚至隔离。在区域的选择中,已确诊病例的空间分布已被视为选择的关键指标。虽然这样的措施已经成功地减缓或者制止了新冠疫情在一些国家的传播,但是该方法因为确诊病例的统计数据通常是有延迟性和粗粒度性而被诟病。为了解决这些问题,本文提出了一个名为C-Watcher的机器学习框架,旨在COVID-19从疫情重灾区传播到目标城市之前,预测出目标城市中每个社区的疫情感染风险。在模型设计上,C-Watcher从百度地图数据中抽取了多种特征来刻画城市中的居民小区。此外,为了在疫情爆发之前将有效的知识及时转移到目标城市,本文设计了一个具有创新性的对抗编码器框架来提取城市之间的共性特征。该方法可以与城市相关的移动特征中抽取有用信息,以达到在非常早期的在目标城市中进行精确的高风险社区预测的目的。通过使用COVID-19爆发早期的真实数据记录,对C-Watcher进行了的实验,实验结果表明C-Watcher能够在疫情早期有效的从大量居民小区中成功筛查出高风险小区。
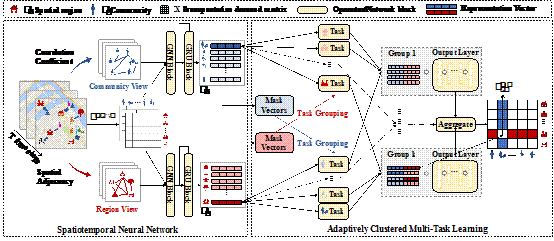
 7、群体感知的多任务出行需求预测
7、群体感知的多任务出行需求预测
Community-Aware Multi-Task Transportation Demand Prediction
出行需求预测在城市治理和多种在线服务中都有广泛应用。但是现有研究主要集中在网格化区域出行需求预测,忽略了不同人群差异化的出行需求。针对这一问题,本文提出了一种全新的自适应互监督多任务图神经网络(Ada-MSTNet),可以有效捕捉不同群体在不同时空场景下的关系。具体地,通过构建多视角空间图和人群图,研究员同时捕捉了不同区域和群体的相关性。同时,本文提出了一种自适应多任务聚类方法,可以更好地在相关性较高的任务之间共享信息。此外,还提出了一种互自监督策略,基于不同视角学习到的表征来监督另一视角中任务的聚类过程。Ada-MSTNet不仅可以在不同群体和区域对应的任务间共享信息,还可以有效防止不相关任务之间的噪音传播。在两个真实数据集上的实验结果也从多个角度证实了我们算法的优势。
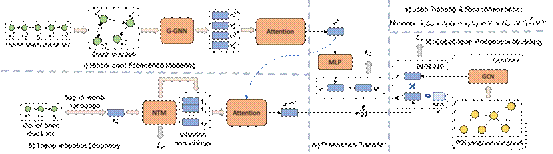
 8、一种基于用户出行意图建模的异地POI推荐方法
8、一种基于用户出行意图建模的异地POI推荐方法
Out-of-Town Recommendation with Travel Intention Modeling
异地POI推荐旨在为跨城出行的用户提供推荐服务。而这些用户通常对目的地区域/城市并不熟悉,并没有足够的历史记录可以借鉴,因而异地推荐的主要挑战也是推荐系统中的一个经典问题——冷启动问题。直观上,用户在异地的行为与用户个人的偏好和用户的出行意图密切有关。而且,用户的出行意图复杂多变,也为准确理解异地用户的出行意图增加了难度。为此,本文提出了一种出行意图可感知的异地出行推荐方法。该方法与传统的异地出行推荐方法的主要区别体现在三个方面:首先,利用图神经网络,通过对历史用户的本地签到行为和异地签到行为进行挖掘,表征用户的本地偏好以及异地的空间地理信息约束;其次,用户的个体出行意图建模为通用出行意图与用户个体偏好的聚合,其中通用出行意图被建模成隐式出行意图的概率分布,并利用主题神经网络模型进行实现;第三,通过多层感知机对本地偏好与异地偏好的迁移进行刻画,同时,利用矩阵分解对异地POI的表征进行估计。最后,通过真实物理世界的跨城出行记录数据进行实验,验证了方法的有效性。而且,该方法所学习到的意图表征可以帮助理解和解释用户的出行意图。
 9、高阶张量的盲块对角化分解
9、高阶张量的盲块对角化分解
A Blind Block Term Decomposition of Higher Order Tensors
张量是高维数据的天然表示方法,张量分解是分析高维数据的重要工具。当前,张量分解已被成功应用于信号处理、数据挖掘、机器学习等领域。特别地,在盲源信号分离问题中,人们通过计算观测信号的高阶统计量(例如四阶累积量)——一个高阶张量的张量分解,可以分离出源信号。然而, 目前计算这种张量分解的方法要求知道相互独立源信号组的个数,以及每组源信号的大小。并且,即使在已知上述信息的条件下,现有方法常常不能收敛,并且抗噪性较差。本文所提出的高阶张量的盲块对角化分解方法成功解决了上述问题。张量的盲块对角化分解是一种通用工具,希望其能在更多场景中获得成功应用,特别是在信号处理与自动聚类中。
 10、基于特征融合的两阶段深度信息补全
10、基于特征融合的两阶段深度信息补全
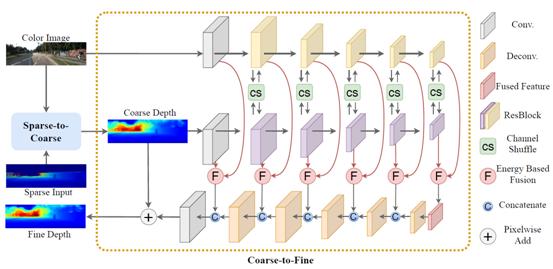
FCFR-Net: Feature Fusion based Coarse-to-Fine Residual Learning for Monocular Depth Completion
论文链接:https://arxiv.org/abs/2012.08270
深度信息补全的目标是以稀疏的深度信息及对应的彩色信息作为输入,恢复更加密集准确的场景深度信息。现有的方法主要把深度信息补全视为单阶段的问题,在这些方法中,特征提取和融合的不够充分,因此限制了方法的性能。为此,本文提出了一个两阶段的残差学习框架,包括sparse-to-coarse阶段和coarse-to-fine阶段。在sparse-to-coarse 阶段,以稀疏的深度信息和对应的彩色信息为输入,本文使用一个简单的CNN网络对稀疏的深度信息进行粗略的填充获得场景密集的深度信息;在coarse-to-fine阶段,以sparse-to-coarse阶段的结果和对应的彩色信息为输入,本文使用通道融合策略和能量融合策略提取获得更加有效的特征信息,因此可以获得更优的场景密集深度信息。本文方法在目前的KITTI depth completion benchmark中排名第二,同时在室内和室外数据集的测试也证明了我们所提方法的先进性。
 11、模拟未标注数据分布用于单标注的医疗图像分割
11、模拟未标注数据分布用于单标注的医疗图像分割
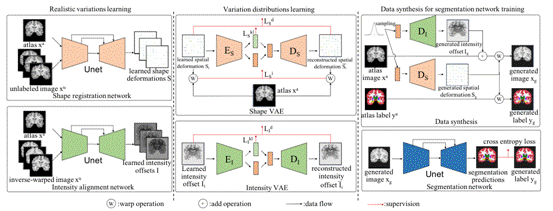
Modeling the Probabilistic Distribution of Unlabeled Data for One-shot Medical Image Segmentation
现有的医疗图像分割网络往往需要大量的有标注的数据才能取得比较好的分割结果。然而3D医疗图像的分割标注需要大量的专业知识和人力成本。因此本文提出一种数据增广的方法,即只利用一张有标注的图片和一些未标注的图片就可以生成大量的真实、多样且有标注的训练数据。本文首先通过图像配准来学习有标注图片到无标注图片之间形状和亮度的真实变换。其次通过VAE网络来学习这些真实变换的分布,并由此生成多样且真实的变换。最后将这些生成的变换作用到有标注图片上生成多样的有标注的图片,并用于分割网络训练。在两个单标注的医疗图像分割数据集上,本文方法超过了SOTA,且实验表明该方法具有更好的泛化能力。
 12、TRQ:基于残差量化的三值神经网络
12、TRQ:基于残差量化的三值神经网络
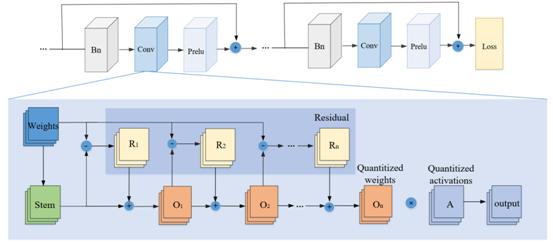
TRQ: Ternary Neural Networks With Residual Quantization
本文认为通过简单的阈值操作进行三值量化导致了较大的精度损失,因而提出一种基于基—残差框架的低误差量化器。该量化器区别于普通阈值操作,通过从全精度权重中提取基与残差信息并结合得到重构三值权重,同时通过递归量化来精细化残差,可以在量化过程中为卷积核保留更多的信息,用以降低量化误差及准确度损失。本文的方法是通用的,可以通过递归地编码残差拓展到多bit量化上。大量的实验数据证明本文提出的方法可以在网络加速下得到较高的识别精度。
来源:凤凰网科技